© 昱琳天使基金 (原名泰格语音技术), http://www.emilyfufoundation.org/
第一步: 执行“中文评估”程序
按一下桌面上的ICON 或者在下面的衔接 Start > All Programs > TigerSpeech
Technology > Mandarin Speech Perception执行“MSP”中文言语感知程序。
第二步:选择已有的课程或者创立新的课程
在左上边有一个“登录课程选择”按钮,按一下那个按钮后会出现一个选择课程
的窗口。课程可以由不同或者相同的用户创立。已有的课程会显示在窗口的表
格中。如果在这个帐号中没有任何课程,在表格中就没有任何显示。在这种情
况下必须创立一个新的课程才能继续进行。如果已有课程的话用户可以双击一
下想要的课程就可以继续。
第三步:系统音量校正
按一下功能键(F8)激活系统音量校正模块。程序默认的校正信号是一个1K赫
兹的单频信号,如果需要换成其他的声音信号作为校正信号,点按一下“浏览”
按钮即可选取所要的信号。注意:软件中的语音信号都是根据单频信号的幅度
校正的。点按一下“连续播放校正声音”,调节音量输出使系统的输出音量在一
个预先设置的值(如65分贝SPL)。
第四步:选择测试组合
在界面的左边显示的是测试组合。目前有三个不同的测试组合(短句,双字
词,单字词)。根据评估的需要选择不同的测试组合。点按所需的测试组合继
续。
第五步:测试内容的选择
在选择了操作内容后,在界面中会显示出目前组合中的测试内容。如中文单字
词组合中有八个不同的测试内容(安静环境,15分贝,10分贝,5分贝,0分
贝,-5分贝,识别阈值,和4通道模拟)。根据不同的需要点按所需的测试内
容。
第六步:测试组的选择
在选择了操作内容后,工具栏的下方会出现一个选择栏,上面会列出所用测试
材料的所有测试组,目前的短句,双字词,和单字词测试材料都有10组不同的
材料。随机选择其中的一组测试组。
第七步:开始新的测试
在选择了测试组之后,点按屏幕上方的”开始START“按钮或者按一下功能键
(F2)就可以开始新的评估测试。
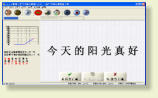
第八步:测试结果显示和打印
在人工耳蜗患者做完了某一测试内容(如短句识别)所需的测试后,界面会显
示出目前测试的结果。这些测试结果会自动存入标准数据库中,用户也可以点
按左上角的“打印”按钮来打印出目前的测试结果。打印的结果如下图所示:



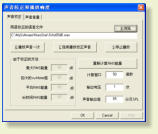





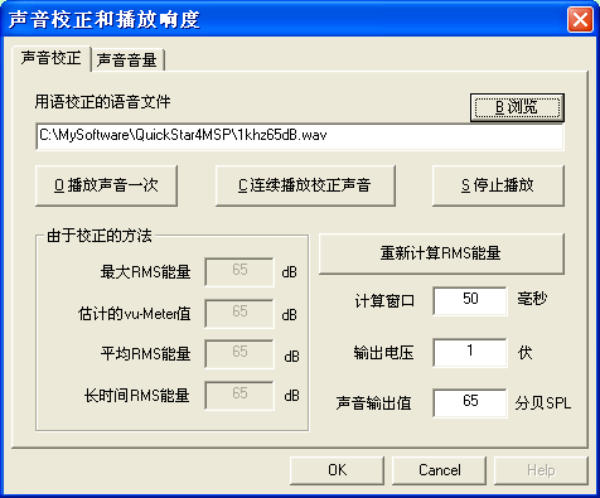
点按一下F8功能键或者选择菜单中的“设置》系统声音校正和播放设置”激活声音校正功能模块。声音校
正功能模块的界面如下图1所示:
整个音量的校正有两部分组成:系统声音校正和声音音量设置。
1.系统声音校正:
系统声音校正是用来调整播放仪器的设置使之输出特定的音量。与系统声音校正最主要的选择是用于
校正的语音文件。其它的参数如计算窗口,输出电压,以及声音输出值则是用来作为一个参考数值来
实时调整播放语音的音量大小。具体的操作如下。
选择用于校正的语音文件。缺省的语音文件是一个1千赫茨的单频信号。此信号已经包含在系统里。
如果使用缺省语音文件,点按一下连续播放校正信号。在系统播放校正声音后,在距离外接喇叭平行
1米远(或者测试者坐的位置)放一个声音测量仪。请调整系统设备的音量设置(如放大器,外接喇
叭或者电脑中的音量设置)使声音测量仪所测的数值达到预设值,缺省的预设值是65分贝SPL。如果
需要其它语音文件用来校正,点按一下“浏览”键找出所需的校正文件。选择了校正文件后,点按一下“
重新计算RMS能量”。其它的步骤与使用缺省语音文件一样。
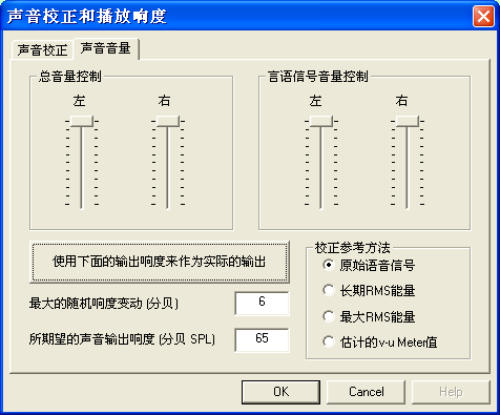
2.声音音量设置:
点按一下“声音音量”选项。上面图2是声音音量设置的界面。
声音音量控制包括电脑音量控制和实时的语音信号调整。其中电脑音量控制包括总音量控制以及言语
信号音量控制。一般来说,在系统校正后不要调整这两个设置。主要的声音音量的设置是依靠实时调
整语音信号完成的。
声音音量的输出可以与校正的音量输出一样或者不一样。缺省值是声音音量的输出与校正的音量输出
是一样的(如65分贝SPL)。如果不一样,点按(选择)“使用下面的输出响度来作为实际的输出”选
项。这个选项有两个参数,一个是允许每个语音信号有一定的波动范围。如果不要波动则设为0。另
外一个参数是所期望的声音输出响度(分贝SPL)。
在决定了声音音量输出强度后,另外一个选择是校正方法的选择。目前提供了四种不同的方法:
•
原始语音信号。这个选项对实际测试中播放的语音并不作任何的调整。所以播出的音量决定于原
始语音信号的响度。如果原始语音信号的RMS值已经调整到与校正信号的RMS值一样,这样的话
输出的音量就是校正的音量。这是目前的系统所使用的缺省方法。
•
长期RMS能量。系统会实时计算每个播放语音信号的长期RMS能量,再与校正信号的长期RMS
能量(见图1)比较。实时调整播放语音信号使调整后的长期RMS能量与校正信号的长期RMS能
量一样。
•
最大RMS能量。系统会实时计算每个播放语音信号的最大RMS能量,再与校正信号的最大RMS
能量(见图1)比较。实时调整播放语音信号使调整后的最大RMS能量与校正信号的最大RMS能
量一样。
•
v-u meter估计值。系统会实时计算每个播放语音信号的v-u meter估计值,再与校正信号的v-u
meter估计值(见图1)比较。实时调整播放语音信号使调整后的v-u meter估计值与校正信号的
v-u meter估计值一样。